MiniCPM-V 4.5模型测试 pk gemini2.5pro 本地8G显卡
-MiniCPM-V 4.5
MiniCPM-V 4.5是MiniCPM-V系列中最新、功能最强的型号。该型号基于Qwen3-8B和SigLIP2-400M,共有8B参数。它比以前的MiniCPM-V和MiniCPM-o型号表现出显着的性能改进,并引入了新的有用特性。MiniCPM-V 4.5的显着特点包括:
最先进的视觉语言能力。MiniCPM-V 4.5在OpenCompass上的平均得分为77.0,这是对8个流行基准测试的综合评估。仅8B参数,它就超越了广泛使用的专有模型,如GPT-4o-update、双子座2.0专业版,以及强大的开源模型,如Qwen2.5-VL72B视觉语言能力,使其成为30B参数下性能最高的MLLM。
高效的高刷新率和长视频理解。MiniCPM-V 4.5现在可以实现96倍的视频令牌压缩率,其中6个448×448视频帧可以联合压缩成64个视频令牌(大多数MLLM通常为1,536个令牌)。这意味着该模型可以在不增加LLM推理成本的情况下感知更多的视频帧。这带来了视频-MME、LVBench、MLVU、MotionBench、FavorBench等上最先进的高刷新率(高达10FPS)视频理解和长视频理解能力。,高效。
可控混合快速/深度思考。MiniCPM-V 4.5支持快速思考,以实现具有竞争力的高效频繁使用,也支持深度思考,以解决更复杂的问题。为了覆盖不同用户场景下的效率和性能权衡,这种快速/深度思考模式可以以高度受控的方式切换。
强大的OCR,文档解析和其他。基于LLaVA-UHD架构,MiniCPM-V 4.5可以处理任何长宽比和高达180万像素(例如1344×1344)的高分辨率图像,使用的视觉标记比大多数MLLM少4倍。该模型实现了OCRBench上的领先性能,超过了专有型号,如GPT-4o-update和双子座2.5RLAIF-V and VisCPM techniques, it features trustworthy behaviors, outperforming GPT-4o-latest on MMHal-Bench, and supports multilingual capabilities in more than 30 languages.
hf测试
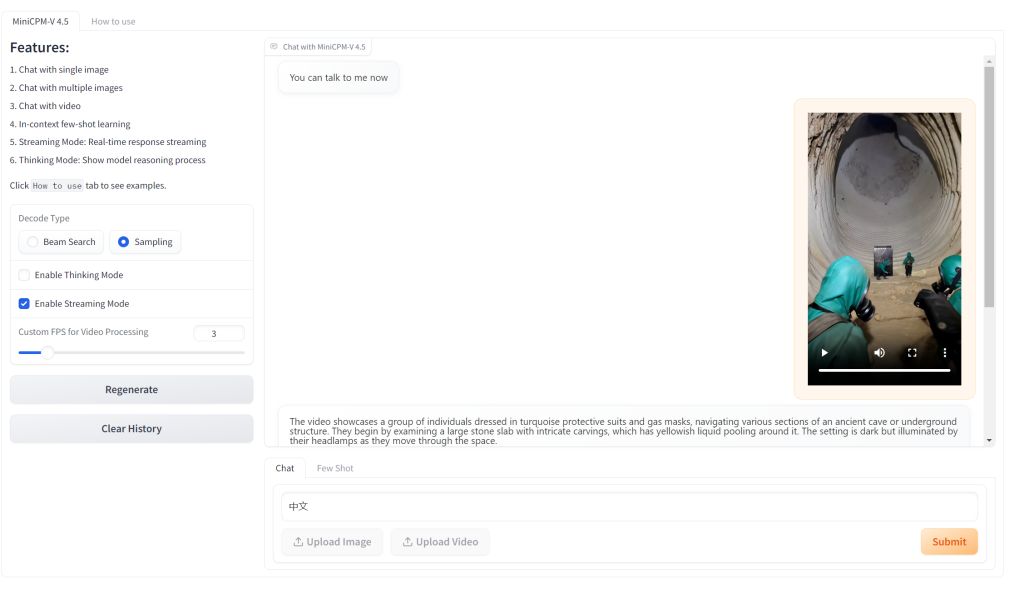
The video showcases a group of individuals dressed in turquoise protective suits and gas masks, navigating various sections of an ancient cave or underground structure. They begin by examining a large stone slab with intricate carvings, which has yellowish liquid pooling around it. The setting is dark but illuminated by their headlamps as they move through the space. As they progress upward on a spiral staircase integrated into the rock formation, more people are seen ascending behind them. Upon reaching higher levels, water starts dripping from above, creating small pools at lower elevations where some team members stand waist-deep to examine submerged bones arranged neatly within circular niches carved into the wall. The exploration continues deeper into the cave-like environment, revealing walls adorned with numerous statues set into alcoves. Water cascades down from openings high above, contributing to the damp conditions below. One individual uses tools like pickaxes and brushes amidst scattered artifacts such as animal skulls and coils of black rope while others survey the surroundings cautiously under the dim light provided by flashlights. In another segment, two team members kneel before a rectangular object embedded in the floor of what appears to be a tunnel lined with concentric rings etched onto its surface. This scene highlights both collaborative investigation efforts among the suited explorers and detailed documentation techniques employed during this archaeological expedition inside these enigmatic subterranean chambers. 视频展示了一群人身着青绿色防护服,戴着防毒面具,在一个古老洞穴或地下建筑的不同区域探索。他们先是查看一块刻有复杂图案的大石板,石板周围有黄色液体汇聚。环境昏暗,但他们走动时,头灯照亮了四周。 他们沿着融入岩层的螺旋楼梯向上行进,身后还有更多人在攀登。到达更高处后,水开始从上方滴落,在地势较低处形成小水洼,一些队员站在齐腰深的水中,查看整齐排列在墙壁圆形壁龛里的水下骨头。 探索继续向类似洞穴的环境深处推进,只见墙壁壁龛中装饰着众多雕像。水从高处开口倾泻而下,加剧了下方的潮湿。一名队员在散落的文物(如动物头骨和黑色绳索卷)中使用鹤嘴锄和刷子等工具,其他人则在手电筒微弱的光线中小心翼翼地查看周围环境。 在另一个片段中,两名队员跪在嵌入地板的一个矩形物体前,这里似乎是一条隧道,隧道表面刻有同心圆环。这一场景既凸显了身着防护服的探险队员之间的协作调查,也展现了在这些神秘地下洞穴中进行考古探险时所采用的详细记录方法。
本地llama.cpp
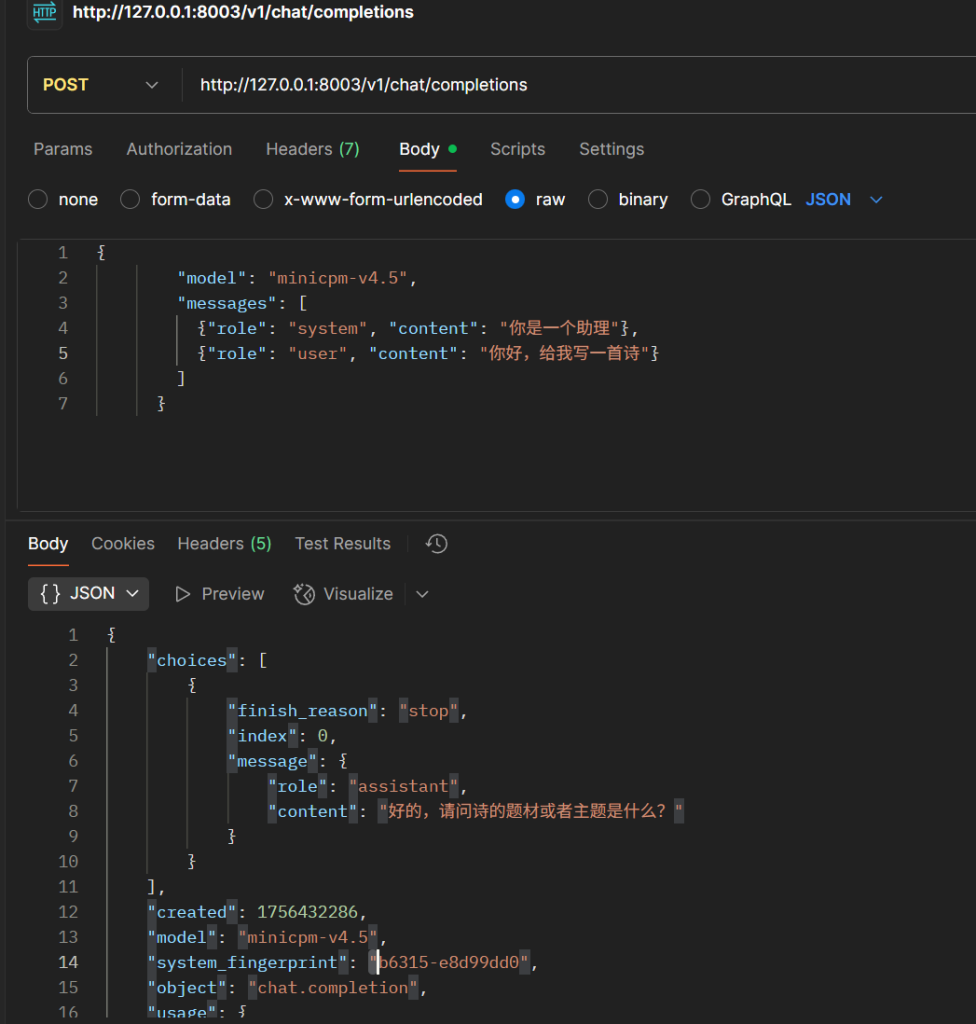
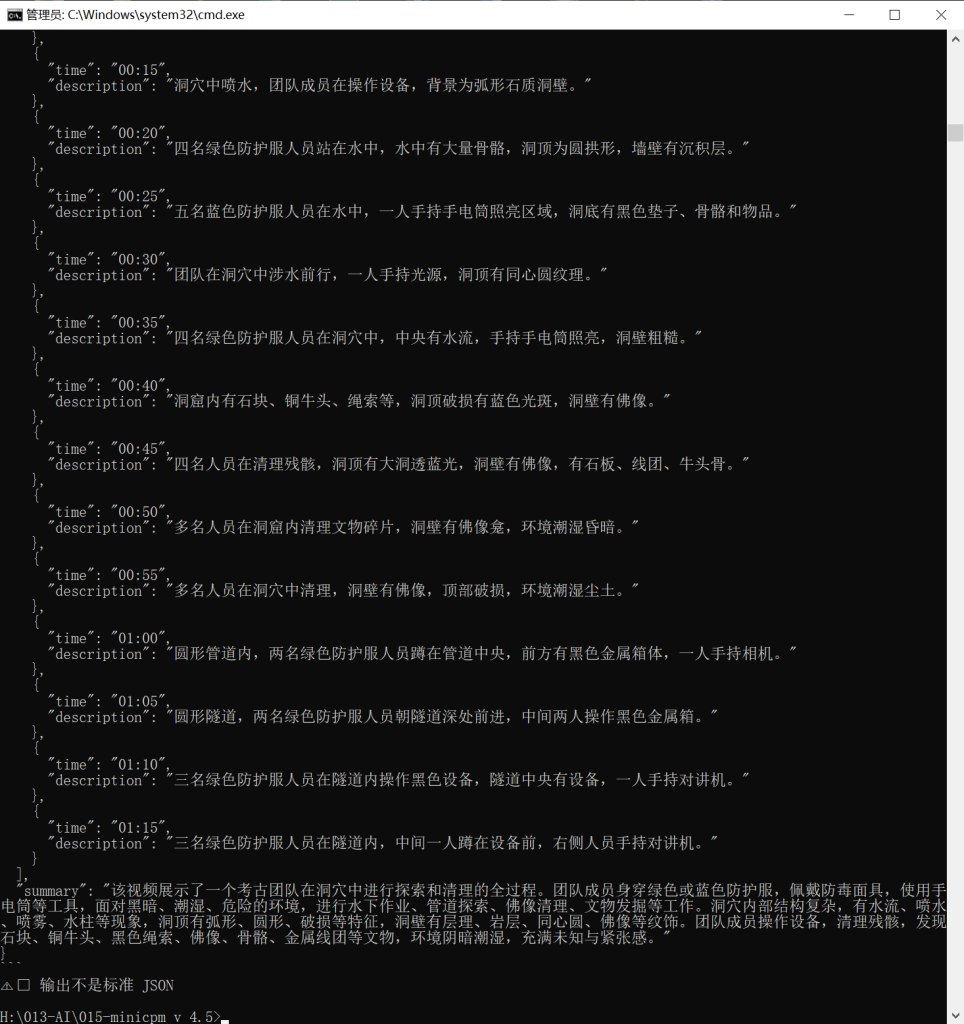
>>> Step2: 逐帧分析...
分析帧 1/16...
分析帧 2/16...
分析帧 3/16...
分析帧 4/16...
分析帧 5/16...
分析帧 6/16...
分析帧 7/16...
分析帧 8/16...
分析帧 9/16...
分析帧 10/16...
分析帧 11/16...
分析帧 12/16...
分析帧 13/16...
分析帧 14/16...
分析帧 15/16...
分析帧 16/16...
>>> Step3: 汇总...
>>> 最终输出:
```json
{
"timeline": [
{
"time": "00:00",
"description": "洞穴内,多名身穿绿色防护服、戴着防毒面具的人在活动,一人攀爬岩壁,水流从上方滴落。"
},
{
"time": "00:05",
"description": "洞穴中央有水流直泻而下,四名穿着绿色防护服的人手持手电筒站在水中,洞内昏暗。"
},
{
"time": "00:10",
"description": "大型管道内,两名绿色防护服人员蹲在管道尽头对黑色矩形物体,两人手持照明设备。"
},
{
"time": "00:15",
"description": "洞穴中喷水,团队成员在操作设备,背景为弧形石质洞壁。"
},
{
"time": "00:20",
"description": "四名绿色防护服人员站在水中,水中有大量骨骼,洞顶为圆拱形,墙壁有沉积层。"
},
{
"time": "00:25",
"description": "五名蓝色防护服人员在水中,一人手持手电筒照亮区域,洞底有黑色垫子、骨骼和物品。"
},
{
"time": "00:30",
"description": "团队在洞穴中涉水前行,一人手持光源,洞顶有同心圆纹理。"
},
{
"time": "00:35",
"description": "四名绿色防护服人员在洞穴中,中央有水流,手持手电筒照亮,洞壁粗糙。"
},
{
"time": "00:40",
"description": "洞窟内有石块、铜牛头、绳索等,洞顶破损有蓝色光斑,洞壁有佛像。"
},
{
"time": "00:45",
"description": "四名人员在清理残骸,洞顶有大洞透蓝光,洞壁有佛像,有石板、线团、牛头骨。"
},
{
"time": "00:50",
"description": "多名人员在洞窟内清理文物碎片,洞壁有佛像龛,环境潮湿昏暗。"
},
{
"time": "00:55",
"description": "多名人员在洞穴中清理,洞壁有佛像,顶部破损,环境潮湿尘土。"
},
{
"time": "01:00",
"description": "圆形管道内,两名绿色防护服人员蹲在管道中央,前方有黑色金属箱体,一人手持相机。"
},
{
"time": "01:05",
"description": "圆形隧道,两名绿色防护服人员朝隧道深处前进,中间两人操作黑色金属箱。"
},
{
"time": "01:10",
"description": "三名绿色防护服人员在隧道内操作黑色设备,隧道中央有设备,一人手持对讲机。"
},
{
"time": "01:15",
"description": "三名绿色防护服人员在隧道内,中间一人蹲在设备前,右侧人员手持对讲机。"
}
],
"summary": "该视频展示了一个考古团队在洞穴中进行探索和清理的全过程。团队成员身穿绿色或蓝色防护服,佩戴防毒面具,使用手电筒等工具,面对黑暗、潮湿、危险的环境,进行水下作业、管道探索、佛像清理、文物发掘等工作。洞穴内部结构复杂,有水流、喷水、喷雾、水柱等现象,洞顶有弧形、圆形、破损等特征,洞壁有层理、岩层、同心圆、佛像等纹饰。团队成员操作设备,清理残骸,发现石块、铜牛头、黑色绳索、佛像、骨骼、金属线团等文物,环境阴暗潮湿,充满未知与紧张感。"
}
``` 输出不是标准 JSONimport os, subprocess, glob, json, base64
from openai import OpenAI
VIDEO_PATH = r"1.mp4"
FRAME_DIR = "frames"
FPS = 0.2
API_URL = "http://127.0.0.1:8003/v1"
MODEL_NAME = "minicpm-v4.5"
def extract_frames(video_path, frame_dir, fps=1):
os.makedirs(frame_dir, exist_ok=True)
subprocess.run([
"ffmpeg", "-i", video_path, "-vf", f"fps={fps}", f"{frame_dir}/frame_%04d.jpg", "-y"
])
def encode_image_to_base64(path):
with open(path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def analyze_single_frame(client, frame_path, seconds):
time_str = f"{seconds//60:02d}:{seconds%60:02d}"
img_b64 = encode_image_to_base64(frame_path)
messages = [
{"role": "system", "content": "你是一个视频逐帧分析助手"},
{"role": "user", "content": [
{"type": "text", "text": f"请描述这张图像(视频时间 {time_str}),输出 JSON 格式:{{\"time\": \"{time_str}\", \"description\": 描述}}。只输出 JSON,不要多余文字。"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{img_b64}"}}
]}
]
resp = client.chat.completions.create(model=MODEL_NAME, messages=messages)
return resp.choices[0].message.content
def merge_results(client, frame_results):
messages = [
{"role": "system", "content": "你是一个视频总结助手"},
{"role": "user", "content": f"以下是逐帧描述:\n{json.dumps(frame_results, ensure_ascii=False, indent=2)}\n请汇总成 JSON 格式:{{\"timeline\": [...], \"summary\": 总结}}。只输出 JSON,不要多余文字。"}
]
resp = client.chat.completions.create(model=MODEL_NAME, messages=messages)
return resp.choices[0].message.content
if __name__ == "__main__":
print(">>> Step1: 抽帧中...")
extract_frames(VIDEO_PATH, FRAME_DIR, FPS)
frames = sorted(glob.glob(f"{FRAME_DIR}/*.jpg"))
client = OpenAI(base_url=API_URL, api_key="none")
print(">>> Step2: 逐帧分析...")
frame_results = []
for i, f in enumerate(frames):
print(f" 分析帧 {i+1}/{len(frames)}...")
result = analyze_single_frame(client, f, i*int(1/FPS))
try:
frame_results.append(json.loads(result))
except:
print(" 单帧结果不是标准 JSON:", result)
print(">>> Step3: 汇总...")
final_result = merge_results(client, frame_results)
print(">>> 最终输出:")
print(final_result)
try:
data = json.loads(final_result)
with open("video_analysis.json", "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
print(">>> JSON 已保存到 video_analysis.json")
except:
print(" 输出不是标准 JSON")